
IMAA Faculty Member Prof. Aswath Damodaran mentioned
From: http://www.valuewalk.com/2018/01/aswath-damodaran-january-2018
Every year, since 1992, I have spent the first week of my year, paying homage to the numbers gods. I collect raw accounting and market data from a variety of raw data providers, and I am grateful to all of them for making my life easier, and I summarize the data on many dimensions, by geography, by industry and by market capitalization. That summarized data, for the start of 2018, can be found on my website, as can the archived data from prior years.
The What?
My dataset includes every publicly traded firm that has a market price available for it, in my raw dataset, and at the start of 2018, it included 43,848 firms, up from the 42,678 firms at the start of 2017. To the question of why I don’t restrict myself to just the biggest, the most liquid or the most heavily followed firms, my answer is a statistical one. Any decision that I make on screening the data or sampling will create biases that will color my results, and while I will not claim to be bias-free (no one is), I would prefer to not initiate it with my sampling.
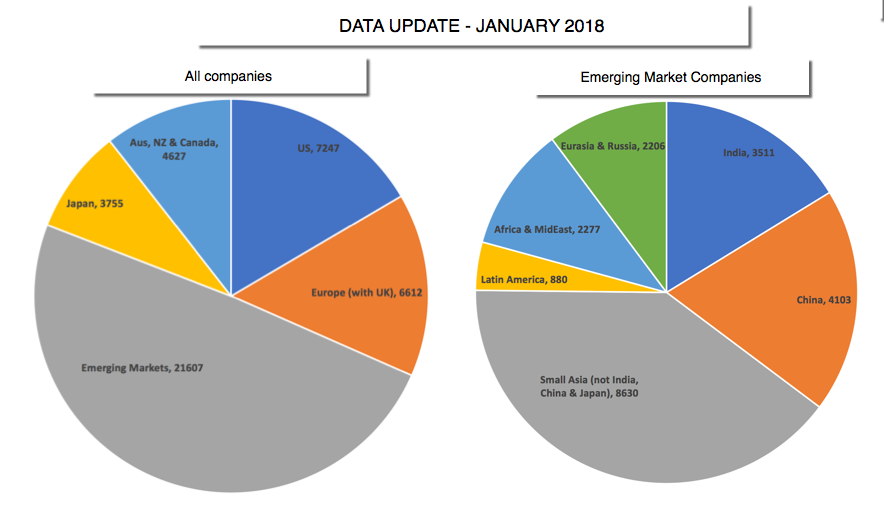
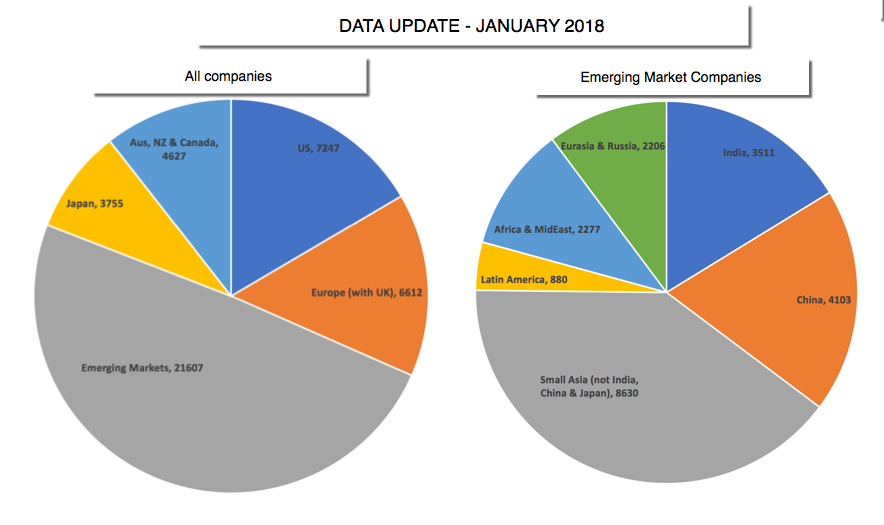
There are 135 countries that are represented in the data, though many have only a handful of firms that are incorporated there. That said, it is worth noting that while the companies are classified by country of incorporation, many have operations in multiple countries. I have classified my firms into five “big” groups: the United States, Europe (EU, UK), Emerging Markets, Japan and Australia/Canada/New Zealand. The pie chart below provides the breakdown:
 |
| Download spreadsheet |
Since the emerging market grouping includes firms from Asia, Latin America, Africa and Eurasia, I also have the data for sub-groups including India, China, Small Asia (other than India, China and Japan), Latin America, Africa & MidEast and Russia/Eurasia. That is pictured in the second pie chart above.Within each geographic group, I break the companies down into 94 industry groupings and the numbers in each grouping are summarized at this link. While some would prefer a finer breakdown, I prefer this coarser grouping because it allows for larger sample sizes, especially as I go to sub-groups. Finally, I compute a range of numbers for each grouping, reflecting my corporate finance biases, and classify them into risk, profitability, leverage and cash return measures in the table below:
| Risk Measures | Cost of Funding | Pricing Multiples |
|---|---|---|
| 1. Beta | 1. Cost of Equity | 1. PE &PEG |
| 2. Standard deviation in stock price | 2. Cost of Debt | 2. Price to Book |
| 3. Standard deviation in operating income | 3. Cost of Capital | 3. EV/EBIT, EV/EBITDA and EV/EBITDA |
| 4. High-Low Price Risk Measure | 4. EV/Sales and Price/Sales | |
| Profitability | Financial Leverage | Cash Flow Add-ons |
| 1. Net Profit Margin | 1. D/E ratio & Debt/Capital (book & market) (with lease effect) | 1. Cap Ex & Net Cap Ex |
| 2. Operating Margin | 2. Debt/EBITDA | 2. Non-cash Working Capital as % of Revenue |
| 3. EBITDA, EBIT and EBITDAR&D Margins | 3. Interest Coverage Ratios | 3. Sales/Invested Capital |
| Returns | Dividend Policy | Risk Premiums |
| 1. Return on Equity | 1. Dividend Payout & Yield | 1. Equity Risk Premiums (by country) |
| 2. Return on Capital | 2. Dividends/FCFE & (Dividends + Buybacks)/ FCFE | 2. US equity returns (historical) |
| 3. ROE – Cost of Equity | ||
| 4. ROIC – Cost of Capital |
The links in the table will lead you to the html versions of the US data, but you can find the excel versions of this data and for the other groupings on my webpage. Since I report more than 150 data items, you may have to work to find what you are looking for but it (or a close variant) should be available somewhere on the site. Since there can be variations on how metrics are computed (like EV/EBITDA or even PE), I summarize my definitions at this link.
The Why?
Much as I would like to claim that my data sharing is driven by altruism and making the world a better place, the reasons are more prosaic. I do this for myself. I enjoy analyzing the data for many reasons:
- Perspective: As our access to data increases, partly because of increased information disclosure on the part of firms, and partly because technology has made it easier to download data, it is ironic that we are more likely to develop tunnel vision now than before we had access to this data. When valuing individual companies, I find that knowing the industry and geographic averages gives me perspective on the numbers that I use for the company. Thus, when valuing Indofoods, an Indonesian food processing company, I can look at typical profit margins for food processing companies in South East Asia, in making my estimates for inputs, and compare my valuation to the pricing of other South East Asian food companies, when I am done.
- Rules of Thumb: Investing is full of rules of thumb that we devised in a different time for a different market, but still are used by investors, often without question. The notion that a stock that trades at a PEG ratio less than one or at a price less than its book value is cheap is deeply engrained in value investing books, but is it true? Looking at the cross sectional distributions of PEG and Price to Book ratios across all companies should give us the answer and allow us to eliminate the rules of thumb that no longer work.
- Curiosity: There are questions that all of us have about companies that the numbers can help answer. Do US companies pay less in taxes than their foreign counterparts? Does growth create or destroy value at companies? The answers to these questions are in the numbers and I find that they provide an antidote to experts who try to pass off opinions as facts.
- Trends and Shifts: Companies change over time, albeit slowly, and these changes have consequences not just for investors, but for governments, taxpayers and workers. One reason that I do not make jarring changes in the way that I classify and report my numbers is to see how these numbers change over time.
In the next two weeks, I will try to summarize what I learn from the data about corporate investment, financing and dividend policy in a series of posts that I have tentatively listed at the end of this post, starting with an update on US equities (and risk premiums) and ending with the a look at market pricing multiples at the end of 2017. Along the way, I will grapple with the rise of crypto currencies and what they might or might not mean for valuation. The motivations for creating these datasets are selfish but I find it pointless to keep them to myself. After all, there is no secret sauce in this data that will lead me to riches, and nothing that someone else with access to the raw data could not generate themselves. If, in the process, a few people are able to use my data in their analyses, I consider them deposits in my “good karma” bank.
The Quirks
Each year that I update the data, there are four challenges that await me. The first relates to data timing, where I try to put myself in the shoes of an investor making investment choices on January 2, 2018. The second is how best to deal with missing data, par for the course since my dataset includes some very small companies in under developed markets. The third is to clean up after the accountants, who are not always consistent in their rules across sectors and geographies. The fourth and final challenge is to find and correct mistakes in the data.
- Timing: All of the data that I have used in my analysis was collected after the close of trading on the last trading day of 2017 (December 29 for most markets) and reflects the most updated data, as of that day. That said, it is worth noting that not all data gets updated at the same rate, with market-set numbers (risk free rate, stock prices, risk premiums) being as of close of trading at the end of the year, but accounting numbers reflecting the most recent financial reports (from October, November and December of 2017). The accounting numbers that I use to compute my financial and pricing ratios are therefore trailing 12-month numbers, if they are updated every quarter, or even 2016 numbers, if they are not updated.
- Missing Data: Information disclosure requirements vary widely across markets and since my dataset spans all markets, there are some items that are available in some markets and not in others. Rather than eliminate companies with missing data, which will both decimate and bias my sample, I keep them in the sample and deal with them the best that I can. For instance, US companies report stock based compensation as an expense item but many non-US companies do not. I report stock based compensation as a percent of total revenues in every market but they are close to reality only in the US data.
- Accounting inconsistencies: I have argued in prior posts that accountants are inconsistent in their treatment of capital expenditures and debt across companies, treating the biggest capital expenditures (R&D) at technology and pharmaceutical companies as operating expenses and ignoring the primary debt (leases) at retail and restaurant companies. Rather than wait for accounting rules to come to their senses, which may take decades, I have capitalized both R&D and lease commitments for all companies and that has consequences for my earnings, invested capital and debt numbers.
- Data mistakes: Working with a spreadsheet with 43,848 companies and 150 data items, I am sure that there are mistakes that have found their way into my summaries, notwithstanding my attempts to catch them. Some of these mistakes are mine but some reflect errors in the raw data. The datasets that are least likely to be affected by mistakes are the US and Global dataset, where I have a combination of the law of large numbers and good disclosure backing me up. Needless to say, if you do find mistakes, please draw my attention to them.
The Caveats
If you find my data useful in your investing, valuation or corporate finance analysis, you are welcome to partake of it. That said, as a number cruncher who both loves numbers and views them with caution, here are a few things to keep in mind.
- Numbers ≠ Facts: While the numbers, once reported, look precise, they are not facts. Thus, when you look at the debt ratios that I report for a sector, it is worth emphasizing that I have capitalized lease commitments and added them to all interest bearing debt (short and long term) to arrive at total debt, yielding a different number than what you may see on a different service. I have tried to be as transparent as I can in making my estimates but they reflect my judgment calls.
- Past is not always prologue: There are some numbers where I report historical trend lines and averages. That is not because I am a die-hard believer in mean reversion, the driving force in many investment philosophies. I believe that knowing history is useful in investing, but trusting it to repeat itself is dangerous.
- Just because everyone does it does not make it right: As you look at the datasets, you will see patterns in investment, financing and dividend policy in sectors. Some sectors, such as telecommunications, are more debt funded than others, say pharmaceuticals, and other pay more dividends (utilities) than others (technology). While there are often good reasons for these differences, there are also bad ones, with inertial on top of that list. The reality is that there are established corporate finance policies in many sectors that no longer make sense, because the sectors have changed fundamentally over time.
As you browse through the numbers, you will notice that I report almost no numbers at the company level. While I do have that data, I am constrained from sharing that data, because I risk stepping on the toes and the legal rights of my raw data providers.
Conclusion
At the end of my data week, I am both exhilarated and exhausted, exhilarated because I can now analyze the data and exhausted because even a number cruncher can get tired of working with numbers. There is information in this data but it will take more care than I have given it so far, but I have the rest of the year to spend looking for those nuggets.
YouTube Video
Links
Data Update Posts
- January 2018 Data Update 1: Numbers don’t lie, or do they?
- January 2018 Data Update 2: US Equities, Let the Good Times Roll!
- January 2018 Data Update 3: A New Tax Code – Value Consequences?
- January 2018 Data Update 4: The Currency Question
- January 2018 Data Update 5: Country Risk
- January 2018 Data Update 6: Cost of Capital – A Global Update
- January 2018 Data Update 7: Growth and Value – Investment Returns
- January 2018 Data Update 8: Debt and Value
- January 2018 Data Update 9: The Cash Harvest – Dividend Policy
- January 2018 Data Update 10: The Pricing Prerogative



Stay up to date with M&A news!
Subscribe to our newsletter